Architecture¶
Deployment¶
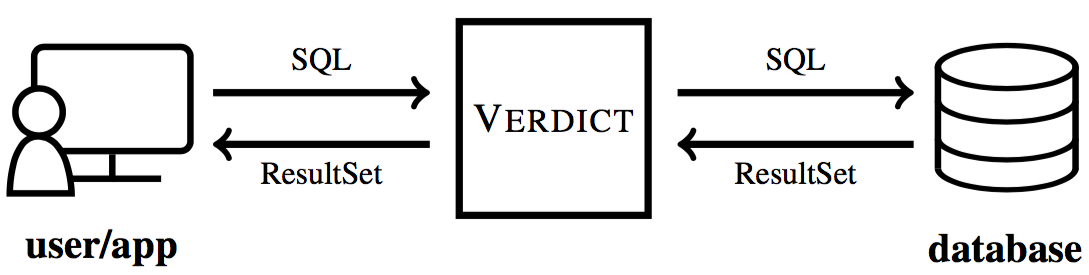
VerdictDB is a thin Java library placed between the user (or an application) and the backend database. Its Python library, i.e., pyverdict, also relies on the Java library. The user can make a connection to VerdictDB either using the standard JDBC or the public API provided by VerdictDB. VerdictDB communicates with the backend database also using JDBC except for special cases (e.g., Apache Spark's SparkSession).
Internal Architecture¶
VerdictDB has the following hierarchical structure. In the list below, an item that comes earlier in the following list depends (only) on the item that comes after the item. For example, JDBC Wrapper relies on VerdictContext. However, JDBC Wrapper does not directly rely on ExecutionContext.
- JDBC Wrapper (public interface)
- VerdictContext (public interface)
- ExecutionContext
- QueryCoordinator
- ExecutionPlan
- ExecutionNode
Connection (VerdictContext)¶
When the user makes a connection to VerdictDB using VerdictContext. VerdictDB's JDBC interface is simply a wrapper over VerdictContext. VerdictContext contains the information sufficient to connect to the backend database. If the user wishes VerdictDB to connect to the backend database using the JDBC interface, it is recommended to pass a connection string; then, VerdictDB creates multiple (10 by default) connections for concurrent query executions. The concurrent query executions make it possible to interleave short, light-weight queries (e.g., metadata retrieval) among long, data-intensive queries (e.g., aggregations).
Execution (ExecutionContext)¶
When the user issues a query, VerdictDB lets VerdictContext create a new instance of ExecutionContext. The instance of ExecutionContext is responsible for the execution of the single query. After the query execution is finished, the ExecutionContext instance is removed from VerdictContext's ExecutionContext list. JVM then may garbage-collect it. For the query execution, ExecutionContext creates a different type of QueryCoordinator instance, as describe below.
Actual Query Processing (QueryCoordinator)¶
Depending on the query type, a different type of QueryCoordinator is created. An important type (or class) is SelectQueryCoordinator. SelectQueryCoordinator parses and converts a given select query into a Java object. The Java object represents relational operations in a platform-independent way (since different DBMS have different SQL syntaxes). Then, SelectQueryCoordinator plans how to execute the Java object. Finally, the plan is executed. See below for more details about the plan.
Plan and Nodes (ExecutionPlan and ExecutionNode)¶
VerdictDB's most internal query executions are based on ExecutionPlan and ExecutionNode. A few exceptions are simple metadata updates. Here, we describe the general concepts about plans and nodes. How the plans and nodes are created, given a select query, is described on this page.
An ExecutionPlan instance is a directed acyclic graph that consists of one or more ExecutionNode instances. An ExecutionNode instance corresponds to a single select query without any subqueries (either projection or aggregation). The directed edge between two ExecutionNode instances indicates the dependency: the parent node depends on some information returned by the child node. Each node runs on a separate Java thread for maximum concurrency.